
7x24小時咨詢熱線
400-660-3310
當前位置 : 好學校 南京正厚軟件技術培訓學校 學習資訊 資訊詳情
MySQL作為存儲數據的工具,它有自己的書寫語言,相信很多小伙伴經過系統學習之后,能夠熟練掌握數據庫定義語言、數據庫操縱語言的語序。但在真正使用SQL過程中,通常要考慮SQL語句的執行效率,特別是查詢語句的效率就需要我們了解SQL語句的執行順序,這樣才能寫出更好地SQL語句,今天就大致梳理一下MySQL查詢語句的執行順序。
n首先SQL語句的基本語法如下:
1、select 查詢字段1,查詢字段2,聚合函數,distinct
2、from 表名
3、join on 表名
4、where 條件
5、group by 分組排列
6、having 條件
7、order by 排序(升序降序)
8、limit 結果限定
n按照以上書寫順序,完整的執行順序應該是這樣:
1、from子句識別查詢表的數據;
2、join on/union用于連接多表數據;
3、where子句基于指定的條件對記錄進行篩選;
4、group by 子句將數據劃分成多個組別,如按性別男、女分組;
5、有聚合函數時,要使用聚集函數進行數據計算;
6、Having子句篩選滿足第二條件的數據;
7、執行select語句進行字段篩選
8、篩選重復數據;
9、對數據進行排序;
10、執行limit進行結果限定。
n如果還不能理解通過下面的例子就能一目了然:
uselect 查詢字段 from 表列表名/視圖列表名 where 條件.
執行順序:先from再where select
uselect 查詢字段 from 表列表名/視圖列表名 where 條件 group by (列列表) having 條件
執行順序:先from再where再group by 再having select
uselect 查詢字段 from 表列表名/視圖列表名 where 條件 group by (列列表) having 條件 order by 列列表
執行順序:先from再where再group by再having再select order by
uselect 查詢字段 from 表1 join 表2 on 表1.列1=表2.列1...join 表n on 表n.列1=表(n-1).列1 where 表1.條件 and 表2.條件...表n.
執行順序:先from 再join再where select
n就是因為有執行順序的限制,在書寫SQL語句時需要注意一下幾點:
uSQL語句是從from開始執行,而不是從select。MySQL在執行SQL查詢語句時,首先是將數據從硬盤加載數據緩沖區中,以便對這些數據進行操作;
uSelect是在from和group by 之后執行,這就導致了無法在where中使用select中設置的字段別名作為查詢條件。如需要查詢男學生的總成績并要升序排列:select sum(score) as “成績總和” from score where sex=“男” order by sum(score);
u聚合函數的計算在where子句之后,所以在where子句中就不能使用聚合函數;
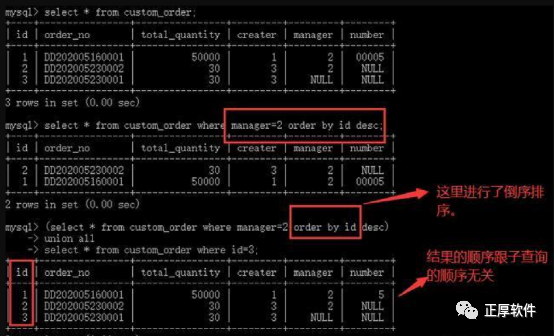
uUnion是排在Order by 之前的,雖然數據庫允許SQL語句對UNION段中的子查詢或者派生表進行排序,但這并不能說明在union操作過后仍保持排序后的順序。如下圖:
u在MySQL中SQL的邏輯查詢時根據以上描述進行的,但MySQL可能并不完全會按照邏輯查詢處理方式進行查詢。MySQL有2個組件:
a)分析SQL語句的Parser;
b)優化器Optimizer;
MySQL在執行查詢之前都會選擇一條自認為的查詢方案去執行,獲取查詢結果。一般情況下都能計算出的查詢方案;
u存在索引時,優化器優先使用索引的插敘條件,當索引為多個時,優化器會直接選擇效率的索引去執行。
相關課程
南京正厚軟件技術培訓學校
認證等級
南京正厚軟件技術培訓學校
已獲好學校V2信譽等級認證
信譽值
與好學校簽訂讀書保障協議:
 官方授權聲明
官方授權聲明
尊敬的平臺會員您好,[南京正厚軟件技術培訓學校]資質文件正在審核中。如需了解[南京正厚軟件技術培訓學校]服務明細或申請試聽服務,
請點擊:聯系客服。



















 粵公網安備 44010602004272號
粵公網安備 44010602004272號